Bilder und andere Dateien vom Indexieren durch Google ausschließen

X-Robots-Tag noindex
Üblicher Weise holt Google (ebenso andere Suchmaschinen) alles, was der Crawler auf einer Website findet, auch in den Suchindex der Suchmaschine. Meist ist das auch so gewollt und viele haben eher ein Problem damit, dass es mit der Suchmaschinenoptimierung nicht ganz so klappt, wie man sich das eigentlich wünscht.
Seiteninhalte
Manchmal ist es aber nicht gewünscht oder sogar schädlich, dass alle Bilder, Dokumente, Lizenz- und Text-Dateien sowie die Sitemap.xml sich plötzlich über die Google-Suche aufspüren lassen. So ist es vielfach üblich, dass Fotografen – oder besser gesagt ehrgeizige Anwaltskanzleien – über die Google Bildersuche nach unerlaubten Kopien suchen und so binnen Sekunden Adressaten für Abmahnungen ausfindig machen können.
Google Bildersuche per Drag & Drop Kopien aufspüren
Der weit verbreitete Glauben, dass man den Zugriff durch Suchmaschinen und die Indexierung in der robots.txt verhindern kann, funktioniert an dieser Stelle nicht. Die robots.txt dient der Steuerung des Crawling, aber nicht der Indexierung!
So lässt sich das Indexieren von Dateien verhindern
Die meisten Hoster sollten die Erweiterung für den Apache-Webserver mod_headers bereitstellen. Damit ist es möglich, die Kopfzeilen (den Header) eines HTTP-Requests zu manipulieren und mit zusätzlichen Informationen anzureichern. Neben dem hier vorgestellten X-Robots-Tag ist sicherlich Cache-Control die am häufigsten eingesetzte Regel.
Um alle JPG–Bilder mit dem Präfix „bild-“ (z.B. „bild-beispielbild.jpg“) mit dem X-Robots-Tag noindex zu versehen, muss der hier aufgeführte Block in die .htaccess-Datei hinzugefügt werden. Die Anweisung Header set X-Robots-Tag „noindex“ sorgt dann unsichtbar für uns menschliche Nutzer dafür, dass Google, Bing, Yahoo & Co. diese Dateien letztendlich nicht mehr in den Suchtrefferlisten ausgeben. Bilder ohne dem Vorsatz „bild-“ sind nicht betroffen.
<ifmodule mod_headers.c>
<FilesMatch "bild-.*\.jpg">
Header set X-Robots-Tag "noindex"
</FilesMatch>
</ifmodule>
HTTP Header anzeigen
Überprüfen lässt sich diese Einstellung, indem ihr euch den HTTP-Header anzeigen lasst. Hierfür gibt es diverse Browser-Erweiterungen wie die Webdeveloper Toolbar und Live HTTP Headers sowie Online-Tools wie headers.cloxy.net. Aber auch mit dem Lynx-Browser und dem Parameter „-head“ lässt sich die Ausgabe des Headers am ganz einfach Bildschirm abrufen.
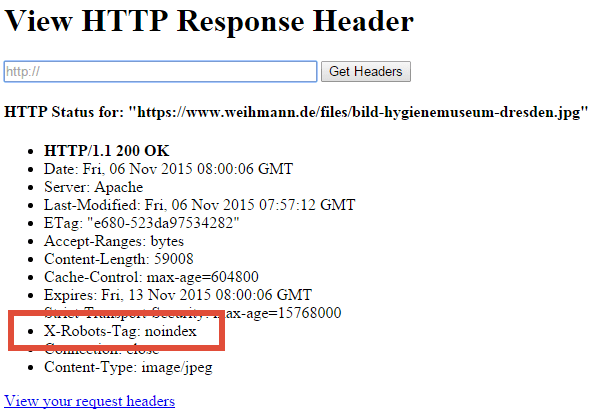
HTTP Response Header Online-Tool – headers.cloxy.net
Sind diese Dateien bereits von den Suchmaschinen indexiert wurden, dauert es natürlich einige Zeit, bis Google & Co. diese nicht mehr auflisten. Hilfreich kann es an dieser Stelle sein, über die Google Search Console diese Dateien noch einmal direkt abrufen zu lassen.
Mehrere Dateien vom Indexieren ausschließen
Wollt ihr für mehrere Dateien – hier im Beispiel sind es die robots.txt, die sitemap.xml, eine readme.txt sowie alle JPG- und PNG-Bilder mit dem Präfix „image-“ – die Aufnahme in den Suchindex verhindern, dann lässt sich dies ganz einfach wie folgt erledigen:
<ifmodule mod_headers.c>
<FilesMatch "robots\.txt|sitemap\.xml|readme\.txt|image-.*\.(jpg|png)">
Header set X-Robots-Tag "noindex"
</FilesMatch>
</ifmodule>
In der 2. Zeile wird nach passenden Dateien für das Muster robots.txt ODER sitemap.xml ODER readme.txt ODER Dateien mit image- und einer beliebigen Anzahl an Folgende-Zeichen, gefolgt von einem Punkt und der Endung jpg ODER png gesucht. Trifft das Muster zu, dann wird in Zeile 3 im Header der X-Robots-Tag auf noindex gesetzt.
Auf diesem Weg lassen sich natürlich alle nur erdenklichen Dateitypen einsetzen. Bei HTML-Dateien ist jedoch oft einfacher, dies über Meta-Angabe zu lösen:
<meta name="robots" content="noindex" />
Noindex für virtuelle Verzeichnisse
Bei einigen CMS-Lösungen ist es oft nicht ganz einfach bzw. manchmal auch fast unmöglich eine Inhaltsseite von der Indexierung auszuschließen. Da hier in der Regel die Datei / das Verzeichnis nicht physisch existiert, funktionieren die oben beschriebenen Vorgehensweisen hier nicht.
Benötigt hatte ich dies zuletzt für 2 Unterseiten bei einer Pagekit-Installation. Die Verzeichnisse /impressum und /datenschutz, die sehr oft nichts im Index einer Suchmaschine verloren haben, galt es hier entsprechend auszustatten. Über das CMS selbst oder einer Erweiterung dafür fand ich keine Lösung, sodass ich hier über die Option per X-Robots-Tag nachdenken musste und schließlich bei StackOverflow fündig wurde.
Environment Variable setzen
In der .htaccess den folgenden Eintrag hinzufügen, um für die Impressum- und der Datenschutz-Seite die Indexierung durch Suchmaschinen auszuschließen (noindex), den auf der Seiten befindlichen Verweisen allerdings zu folgen (follow). Das dürfte das am häufigsten vorkommende Szenario sein.
SetEnvIf REQUEST_URI "^/(impressum|datenschutz)" NOINDEX Header set X-Robots-Tag "noindex, follow" env=REDIRECT_NOINDEX
Eine kurze Überprüfung mit Hilfe der Webdeveloper-Erweiterung für Google Chrome zeigte, das der Response Header korrekt mit „noindex, follow“ übertragen wurde und diese Seiten künftig nicht über Google, Bing & Co. zu finden sein werden.

Noindex Response Header
Typische Seiten, die nicht im Google-Index auftauchen müssen (die Anforderungen können aber durchaus hiervon abweichen), sind u.a. sicherlich:
- Impressum
- Datenschutzhinweise
- AGB
- Sitemap
- Archiv-Seiten
Beispielbild, welches per X-Robots-Tag auf noindex gesetzt wurde

Noindex-Beispiel: Hygienemuseum Dresden – https://www.weihmann.de/files/bild-hygienemuseum-dresden.jpg
Freifahrtsschein zum Bilderklau?
Das ist natürlich kein Aufruf von mir, sich nun Bilder überall im Netz zusammen zu klauen!
Berechtigte Ansprüche Dritter sind nicht nur für mein Rechtsempfinden absolut wichtig. Allerdings hört man immer mal wieder von Fällen, bei denen Blogger und Webseitenbetreiber für die Nutzung von Bildern abgemahnt wurden, obwohl entsprechende Lizenzen bei Stockfoto-Plattformen korrekt erworben wurden. Ebenso kann dies Affiliates betreffen, die im guten Glauben freigegebene Produktfotos der Advertiser einsetzen und letztendlich doch eine Urheberrechtsverletzung begehen.
Wer also mit Bilder dieser Art nicht unbedingt Traffic über die Bildersuche bekommen möchte, ist mit dem Einsatz des hier beschriebenen Verfahrens auf einer etwas sicheren Seite. Zumindest schließt ihr die mühelose Auffindbarkeit über die ganz einfachen Wege aus. Vergesst das Testen nicht! Denn bereits ein Buchstabendreher im Filename oder ein vergessener Punkt in der .htaccess-Datei lassen die Änderung am HTTP-Header hinfällig werden.
Fragen, Hinweise und Bemerkungen bitte wie gehabt in den Kommentaren hinterlassen. Wer mag, darf auf diese Anleitung natürlich in den sozialen Netzwerken oder auf der eigenen Website verweisen.
2 Responses
Leider erscheint immer ein Server-Error. Es geht wohl nicht bei allen Hostern mit Dieser Methode
Zumindest mod_headers sollte doch eigentlich kein Hoster unterbinden. Die Beispiele sind aber nur für Apache-Webserver. Nginx nutze ich nicht, hier könnte das etwas anders aussehen.